학습목표
+ 분류분석의 개요와 기법을 이해
- 분류분석: 레코드의 특정 속성의 값이 범주형으로 정해져 있으며 데이터의 실체가 어떤 그룹에 속하는지 예측하는데 사용되는 기법
- 사기방지모형, 이탈모형, 고객세분화모형 등을 개발할 때 활용되는 마이닝 기법
- 분류 기법에는 로지스틱회귀분석, 의사결정나무, 베이지안 분류, 인공신경망, SVM등에서 활용
+ 의사결정나무
- 의사결정나무 분석은 분류함수를 의사결정 규칙으로 이뤄진 나무모양으로 그리는 방법
- 의사결정 문제를 시각화해 의사결정이 이뤄지는 시점과 성과를 한 눈에 볼 수 있으며 계산결과가 의사결정나무에 직접 나타나게 돼 분석이 간편
- 의사결정나무의 종류로는 가장 많이 활용되고 있는 CART과 C4.5와 CHAID등 다양한 문제를 해결
1) 분류분석과 예측분석
1. 분류분석의 정의
- 데이터가 어떤 그룹에 속하는지 예측하는데 사용되는 기법
- 클러스터링과 유사하지만, 분류분석은 각 그룹이 정의되어 있다
- 교사학습에 해당하는 예측기법
(교사학습:입력 데이터와 그에 상응하는 출력(레이블 또는 타깃)을 포함하는 데이터 세트를 사용하여 모델을 훈련시키는 것)
2. 예측분석의 정의
- 시계열분석처럼 시간에따른 값 두개만을 이용해 앞으로의 매출 또는 온도 등을 예측하는 것
- 모델링을 하는 입력 데이터가 어떤 것인지에 따라 특성이 다르다
- 여러 개의 다양한 설명변수(독립변수)가 아닌, 한 개의 설명변수로 생각하면 된다
3. 분석분류, 예측분석의 공통점과 차이점
가) 공통점 : 레코드의 특정 속성의 값을 미리 알아맞히는 점
나) 차이점
- 분류 : 레코드(튜플)의 범주형 속성의 값을 알아맞히는 것
- 예측 : 레코드(튜플)의 연속형 속성의 값을 알아맞히는 것
4. 분류, 예측의 예
가) 분류
- 학생들의 국어, 영어, 수학 점수를 통해 내신등급을 알아맞히는 것
- 카드회사에서 회원들의 가입 정보를 통해 1년 후 신용등급을 알아맞히는 것
나) 예측
- 학생들의 여러 가지 정보를 입력하여 수능점수를 알아맞히는 것
- 카드회사 회원들의 가입정보를 통해 연 매출액을 알아맞히는 것
5. 분류 모델링
- 신용평가모형(우량,불량) / 사기방지모형(사기,정상) / 이탈모형(이탈,유지) / 고객세분화(VVIP,VIP,GOLD,SILVER,BRONZE)
6. 분류 기법
- 로지스틱 회귀분석 / 의사결정나무, CART / 나이브 베이즈 분류 / 인공신경망 / 서포트 벡터머신 / k최근접 이웃
/ 규칙기반의 분류와 사례기반추론
2) 로지스틱 회귀분석(Logistic Regression)
- 반응변수가 범주형인 경우 적용되는 회귀분석모형
- 새로운 설명변수(예측변수)가 주어질 때 반응변수의 각 범주(집단)에 속할 확률이 얼마인지를 추정(예측모형)하여,
추정 확률을 기준치에 따라 분류하는 목적(분류모형)으로 활용
- 이때 모형의 적합을 통해 추정된 확률은 사후확률(Posterior Probability) 이라고 한다
- exp(β1) : 나머지 변수(x_1, ..., x_k)가 주어질 때, x_1이 한 단위 증가할 때마다 성공(Y=1)의 오즈가 몇 배 증가하는지를 나타내는 값
(오즈(Odds)는 성공할 확률이 실패할 확률의 몇 배인지를 나타내는 확률이며, 오브비는 두 오즈의 비율 )
- 그래프의 형태 : 설명변수가 한 개(x1)인 경우 해당 회귀계수 β1의 부호에 따라 S자 모양(β1>0) 또는 역 S자 모양(β1<0)
- 표준 로지스틱 분포의 누적분포함수로 성공확률 추정

- 선형회귀분석과 로지스틱 회귀분석의 비교
- glm()함수를 이용해 로지스틱 회귀분석 실행
#family=binomial은 로지스틱 회귀분석시 이항식으로
R코드 : b<-glm(종속변수~독립변수1 + ...+ 독립변수k, family=binomial, data=데이터셋명)

3) 의사결정나무
1. 정의
- 의사결정나무는 분류함수를 의사결정 규칙으로 이뤄진 나무 모양으로 그리는 방법
- 나무구조는 연속적으로 발생하는 의사결정 문제를 시각화해 의사결정이 이뤄지는 시점과 성과를 한눈에 볼 수 있게 한다
- 계산 결과가 의사결정나무에 직접 나타나기 때문에 해석이 간편
- 의사결정나무는 주어진 입력값에 대하여 출력값을 예측하는 모형으로 분류나무와 회귀나무 모형이 있다
의사결정나무의 구성요소
뿌리마디(Root Node) : 시작되는 마디. 전체자료 포함
자식마디(Child Node)
: 하나의 마디로부터 분리되어 나간 2개 이상의 마디들
부모마디(Parent Node) : 주어진 마디의 상위 마디
끝마디(Terminal Node) : 자식마디가 없는 마디
중간마디(Internal Node) : 부모마디와 자식마디가 모두 있는 마디
가지(Branch) : 뿌리마디로부터 끝마디까지 연결된 마디들
깊이(Depth) : 뿌리마디부터 끝마디까지의 중간마디들의 수
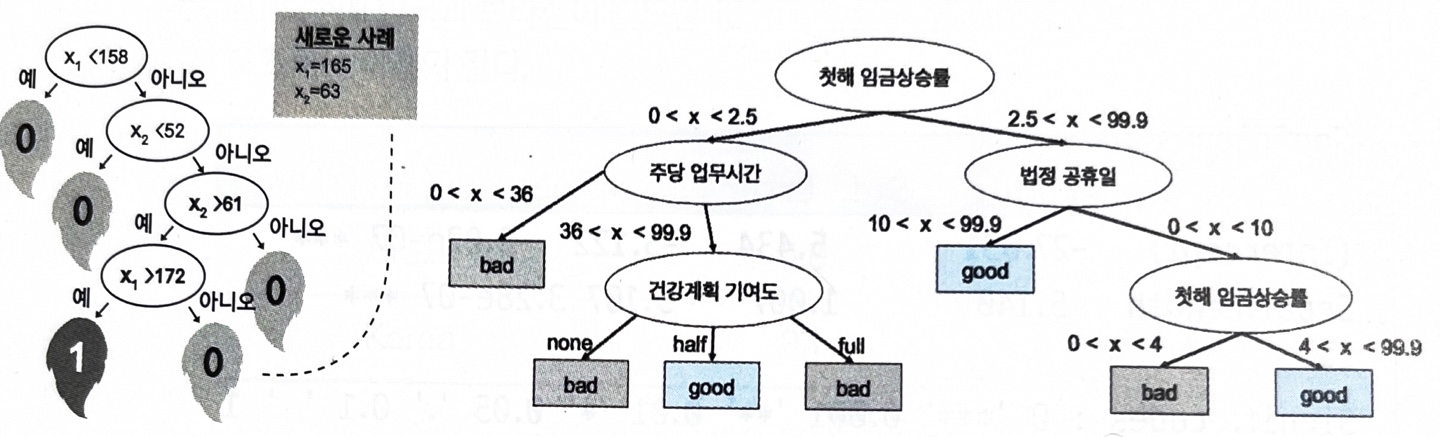
2. 예측과 해석력
- 기대 집단의 사람들 중 가장 많은 반응을 보일 고객의 유치방안을 예측하고자 하는 경우에는 예측력에 치중
- 신용평가에서는 심사 결과 부적격 판정이 나온 경우 고객에게 부적격 이유를 설명해야하므로 해석력에 치중
3. 의사결정나무의 활용
가) 세분화 : 데이터를 비슷한 특성을 갖는 몇 개의 그룹으로 분할해 그룹별 특성을 발견하는 것
나) 분류 : 여러 예측변수들에 근거해 관측개체의 목표변수 범주를 몇 개의 등급으로 분류하고자 하는 경우에 사용하는 기법
다) 예측 : 자료에서 규칙을 찾아내고 이를 이용해 미래의 사건을 예측하고자 하는 경우
라) 차원축소 및 변수선택 : 매우많은 수의 예측변수 중에서 목표변수에 작용하는 규칙을 파악하고자 하는 경우
마) 교호작용효과의 파악
- 여러 개의 예측변수들을 결합해 목표변수에 작용하는 규칙을 파악하고자 하는 경우
- 범주의 병합 또는 연속형 변수의 이산화 : 범주형 목표변수의 범주를 소수의 몇개로 병합하거나 연속형 목표변수를 몇 개의 등급으로 이산화 하고자 하는 경우에
4. 의사결정나무의 특징
기) 장점
- 결과를 누구에게나 설명하기 용이
- 모형을 만드는 방법이 계산적으로 복잡하지 않음
- 대용량 데이터에서도 빠르게 만들 수 있음
- 비정상 잡음 데이터에 대해서도 민감함이 없이 분류할 수 있다
- 한 변수와 상관성이 높은 다른 불필요한 변수가 있어도 크게 영향을 받지 않는다
- 설명변수나 목표변수에 수치형변수와 범주형변수를 모두 사용가는
- 모형분류 정확도가 높음
나) 단점
- 새로운 자료에 대한 과대적합이 발생할 가능성이 높음
- 분류 경계선 부근의 자료값에 대해서 오차가 큼
- 설명변수 간의 중요도를 판단하기 쉽지 않음
5. 의사결정나무의 분석과정
- 의사결정나무의 형성과정은 크게 성장 > 가지치기 > 타당성평가 > 해석 및 예측 으로 이루어진다
1번 성장단계 : 각 마디에서 적절한 최적의 분리규칙(Splitting Rule)을 찾아서 나무를 성장시키는 과정으로
적절한 정지규칙(Stopping Rule)을 만족하면 중단한다
2번 가지치기단계 : 오차를 크게 할 위험이 높거나 부적절한 추론규칙을 가지고 있는 가지 또는 불필요한 가지를 제거하는 단계
3번 타당성 평가단계 : 이익도표(Gain Chart), 위험도표(Risk Chart), 혹은 시험자료를 이용하여 의사결정나무를 평가하는 단계
4번 해석및예측 단계 : 구축된 나무모형을 해석하고 예측모형을 설정한 후 예측에 적용하는 단계
6. 나무의 성장
- 훈련자료를 (xi, yi) i=1,2,...,n으로 나타낸다. 여기서, xi=(xi1,...,xip)
- 나무모형의 성장과정은 x들로 이루어진 입력 공간을 재귀적으로 분할하는 과정
가) 분리규칙(Splitting Rule)
- 분리변수가 범주형{1, 2, 3, 4}인 경우, A=1,2,4와 A^c=3으로 나뉨
- 최적 분할의 결정은 불순도 감소량을 가장 크게하는 분할
- 각 단계에서 최적 분리기준에 의한 분할을 찾은 다음 각 분할에 대하여도 동일한 과정을 반복
나) 분리기준(Splitting Criterion)
- 이산형 목표변수
> 카이제곱 통계량 p값 : P값이 가장 작은 예측변수와 그때의 최적분리에 의해서 자식마디를 형성
> 지니 지수 : 지니 지수를 감소시켜주는 예측변수와 그 떄의 최적분리에 의해서 자식마디를 형성
> 엔트로피 지수 : 엔트로피 지수가 가장 작은 예측변수와 이때의 최적분리에 의해 자식마디를 형성
- 연속형 목표변수
> 분산분석에서 F통계량 : P값이 가장 작은 예측변수와 그때의 최적분리에 의해서 자식마디를 형성
> 분산의 감소량 : 분산의 감소량을 최대화 하는 기준의 최적분리에 의해서 자식마디를 형성
다) 정지규칙(Stopping Rule)
- 더 이상 분리가 일어나지 않고, 현재의 마디가 끝마디가 되도록 하는 규칙
- 정지기준(Stopping Criterion) : 의사결정나무의 깊이를 지정. 끝마디의 레코드 수의 최소 개수를 지정
7. 나무의 가지치기(Pruning)
- 너무 큰 나무모형은 자료를 과대적합하고 너무 작은 나무모형은 과소적합 할 위험이 있음
- 나무의 크기를 모형의 복잡도로 볼 수 있으며 최적의 나무크기는 자료로부터 추정하게 된다
- 일반적으로 사용되는 방법은 마디에 속하는 자료가 일정 수(가령5)이하일 때 분할을 정지하고
비용-복잡도 가지치기(Cost Complexity Runing)를 이용하여 성장시킨 나무를 가지치기 한다
4) 불순도의 여러 가지 측도
- 목표변수가 범주형 변수인 의사결정나무의 분류규칙을 선택하기 위해서 카이제곱 통계량, 지니지수, 엔트로피 지수 활용
가) 카이제곱 통계량 : 각 셀에 대한 ((실제도수-기대도수)의 제곱/기대도수)의 합 (기대도수 = 열의 합계x합의 합계/전체합계)
나) 지니지수 : 노드의 불순도를 나타내는 값. 지니지수 값이 클수록 이질적(Diversity)이며 순수도(Purity)가 낮다
다) 엔트로피 지수 : 열역학에서 쓰는 개념으로 무질서 정도에 대한 측도
- 엔트로피 지수의 값이 클수록 순수도(Purity)가 낮다
- 엔트로피 지수가 가장 작은 예측 변수와 이때의 최적분리 규칙에 의해 자식마디 형성
5) 의사결정나무 알고리즘
1. CART(Classification and Regression Tree : 분류 and 회귀 나무)
- 앞에서 설명한 방식의 가장 많이 활용되는 의사결정나무 알고리즘
- CART는 데이터를 분할하고 예측하는 과정을 트리 형태로 나타냄
- 불순도의 측도로 출력(목적)변수가 범주형일 경우 지니지수 를 이용
- 연속형인 경우 분산을 이용한 이진분리(Binary Split) 사용
- 개별 입력변수 뿐만 아니라 입력변수들의 선형결합들 중에서 최적의 분리를 찾을 수 있음
- 분류는 주어진 입력 데이터를 여러 범주 중 하나로 분류하는 작업, 회귀는 연속적인 결과를 예측하는 작업
2. C4.5와 C5.0
- CART와 다르게 각 마디에서 다지분리(Multiple Split)이 가능
- 범주형 입력변수에 대해서는 범주의 수만큼 분리가 일어남
- 불순도의 측도 : 엔트로피 지수
3. CHAID(CHi-Squared Automathic Interaction Detection)
- 상호작용을 감지하여 트리 형태의 모델을 생성하는 의사결정 트리 알고리즘
- 가지치기를 하지 않고 적당한 크기에서 나무모형의 성장을 중지
- 입력변수(독립변수)가 반드시 범주형 변수 > 각 노드에서 범주형 변수의 수준에 따라 데이터를 분할
- 불순도의 측도 : 카이제곱 통계량 (각 분할에서 카이제곱 검정을 사용하여 독립변수와 종속변수 간의 관계의 유의성을 평가)
'ADsP(데이터 분석 준전문가) > 개념정리' 카테고리의 다른 글
| [3-5. 정형 데이터 마이닝] 4. 인공신경망 분석 (0) | 2024.01.16 |
|---|---|
| [3-5. 정형 데이터 마이닝] 3. 앙상블 분석 (0) | 2024.01.15 |
| [3-5. 정형 데이터 마이닝] 1.데이터 마이닝의 개요 (3) | 2024.01.12 |
| [3-4. 통계분석] 6.주성분 분석 (2) | 2024.01.10 |
| [3-4. 통계분석] 5.다차원척도법 (1) | 2024.01.10 |

